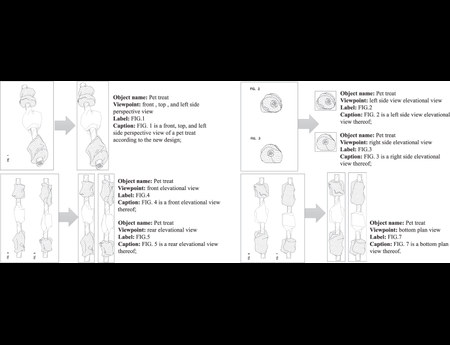
DeepPatent2: A Large-Scale Benchmarking Corpus for Technical Drawing Understanding

by Kehinde Ajayi, Xin Wei, Martin Gryder, Winston Shields, Jian Wu, Shawn M. Jones, Michal Kucer, and Diane Oyen
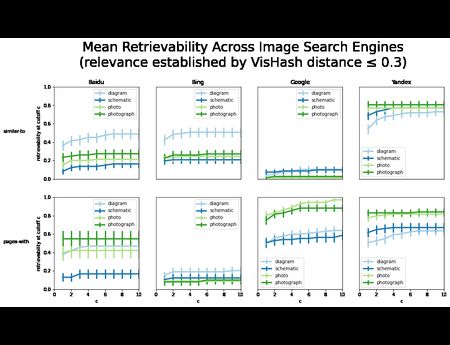
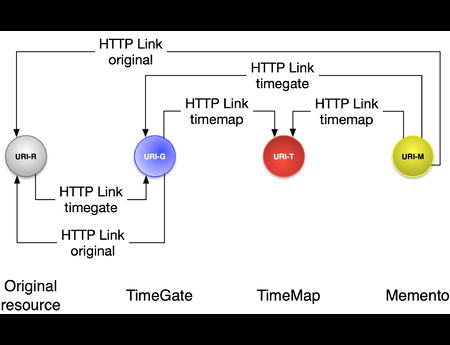
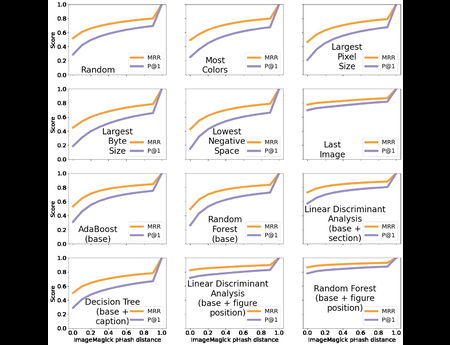
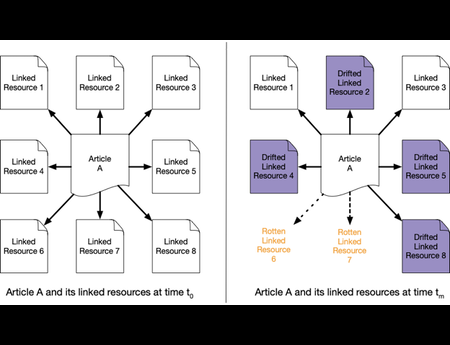
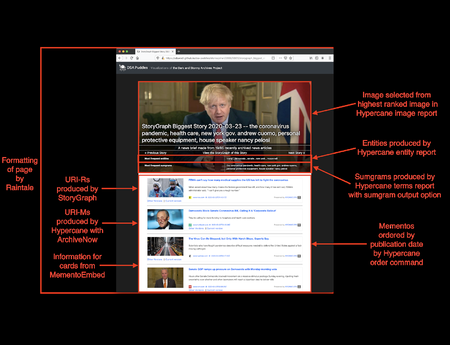
Recent advances in computer vision (CV) and natural language processing have been driven by exploiting big data on practical applications. However, these research fields are still limited by the sheer volume, versatility, and diversity of the available datasets. CV tasks, such...
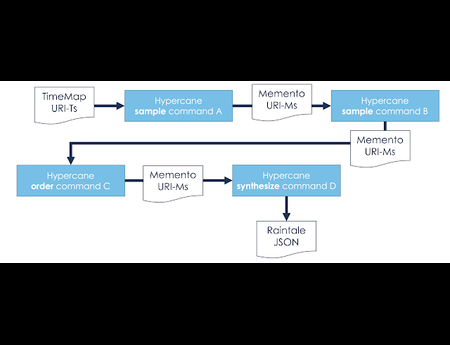
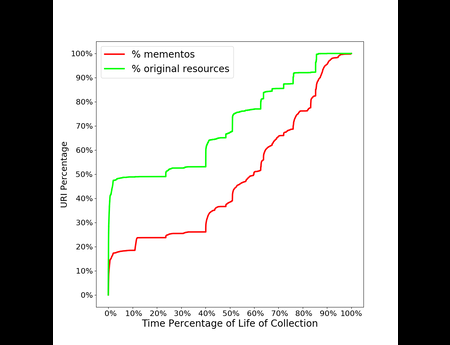
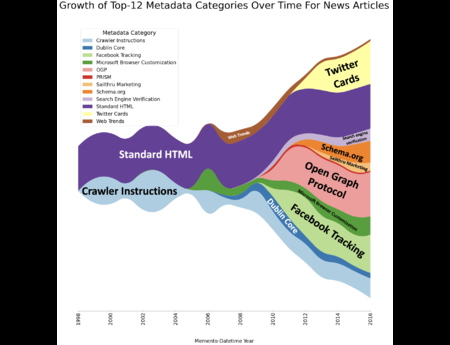
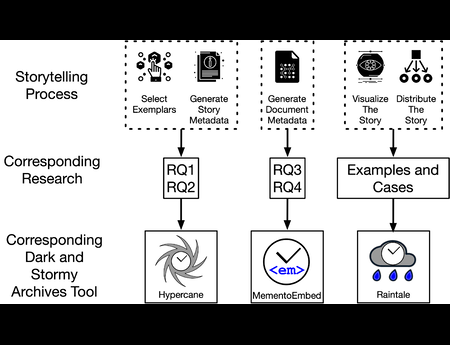
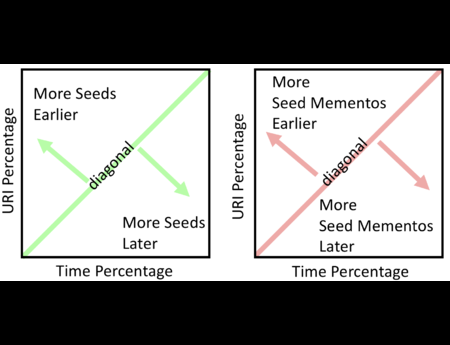
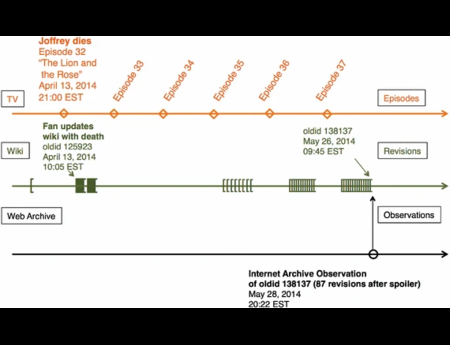
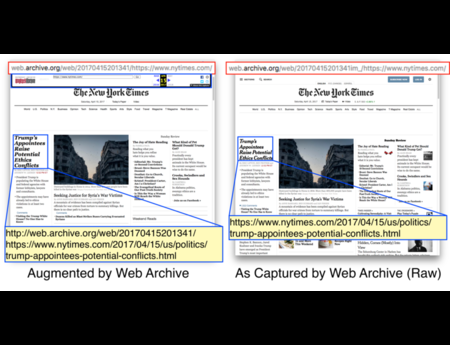
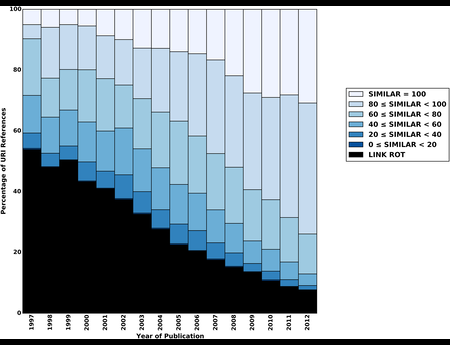
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}