
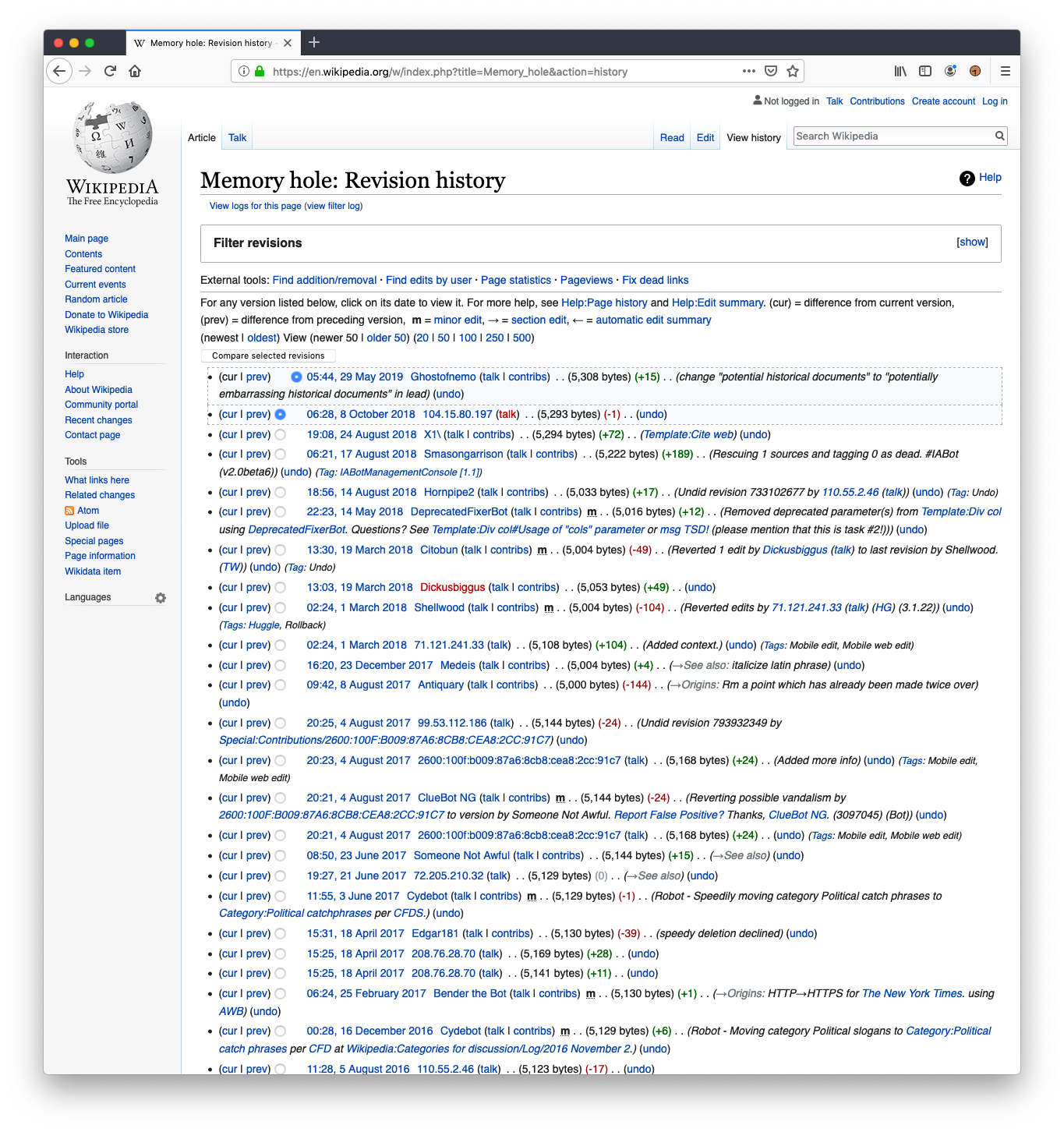
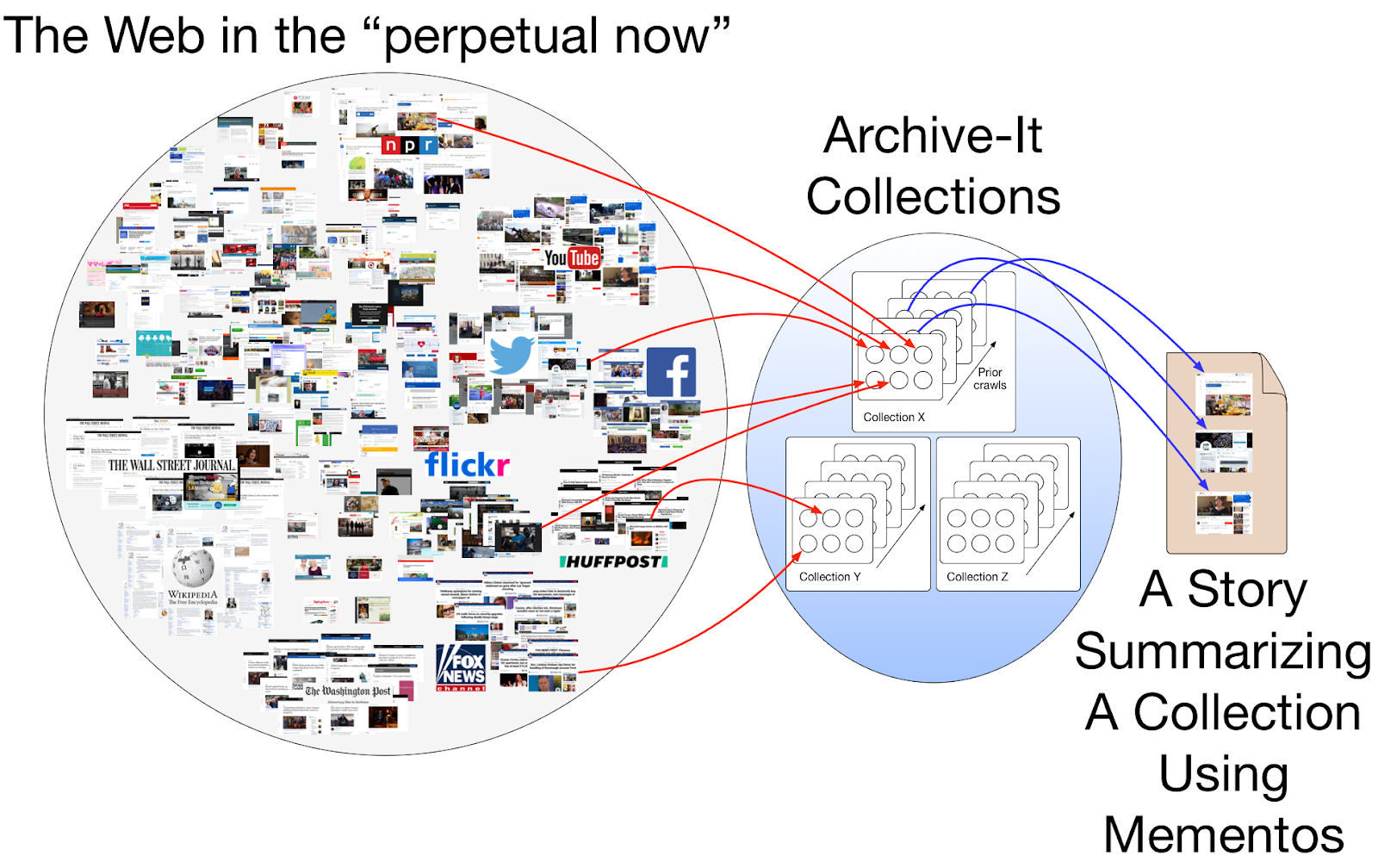
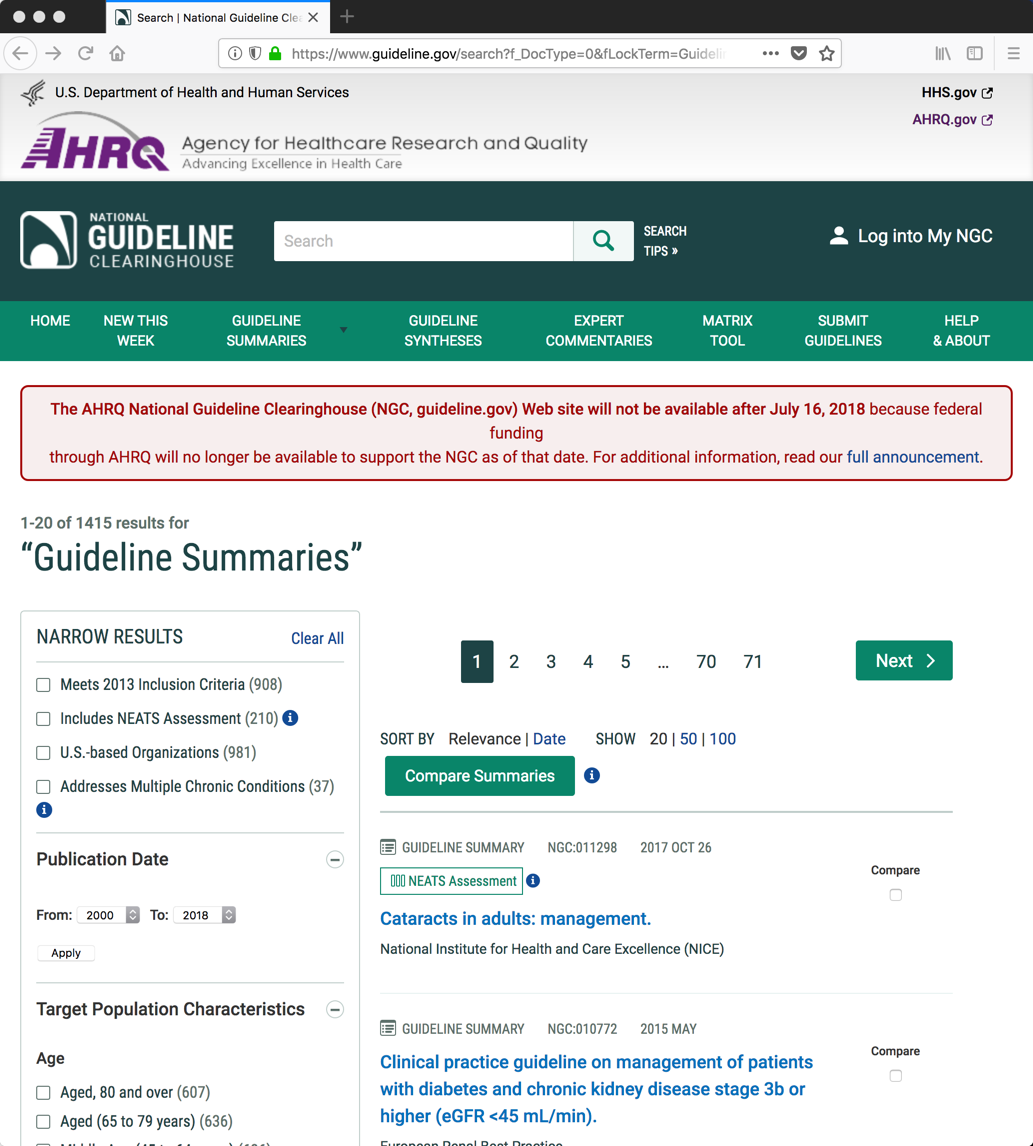
ECCV 2022 and DIRA 2022 Trip Report

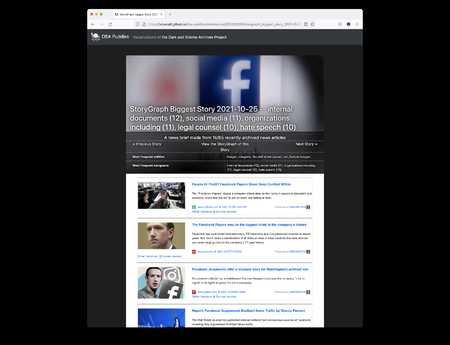
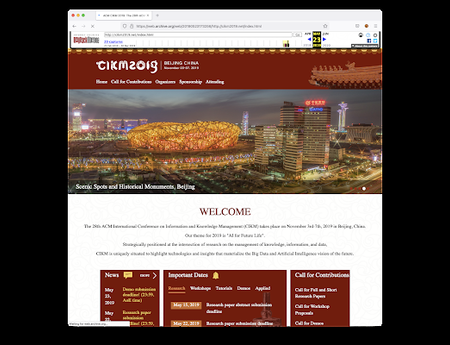
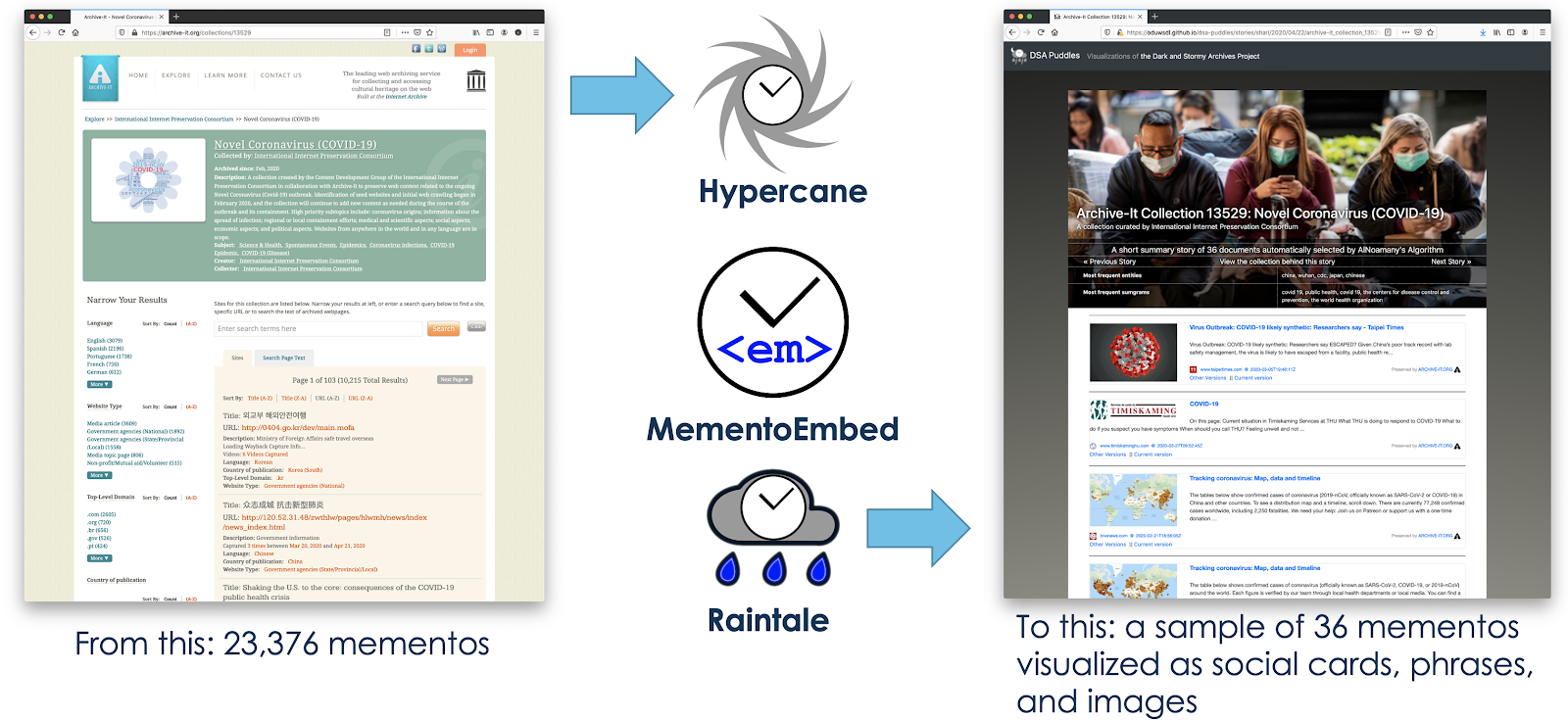
I had a paper accepted to the Drawings and abstract Imagery: Representation and Analysis (DIRA) workshop, allowing me to attend the 17 th European Conference on Computer Vision 2022 (ECCV 2022) in Tel Aviv, Israel, from October 23 - 27. ECCV 2022 is a large conference with att...

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
){kind=link}
){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
%20Doctoral%20Consortium%20Trip%20Report){kind=link}
{kind=link}
{kind=link}
{kind=link}
%20Annual%20Meeting%202017){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
%20Page,%20Today's%20Image?){kind=link}
{kind=link}