VizGenie: Toward Self-Refining, Domain-Aware Workflows for Next-Generation Scientific Visualization

by Ayan Biswas, Terece L. Turton, Nishath Rajiv Ranasinghe, Shawn Jones, Bradley Love, William Jones, Aric Hagberg, Han-Wei Shen, Nathan DeBardeleben, Earl Lawrence
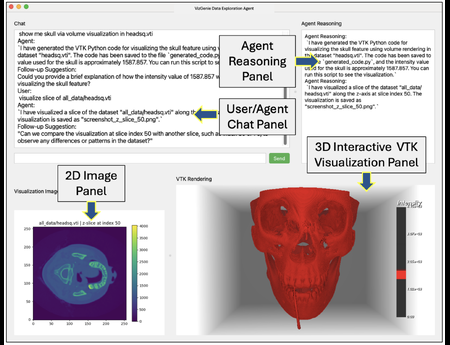
We present VizGenie, a self-improving, agentic framework that advances scientific visualization through large language model (LLM) by orchestrating of a collection of domain-specific and dynamically generated modules. Users initially access core functionalities–such as thresho...

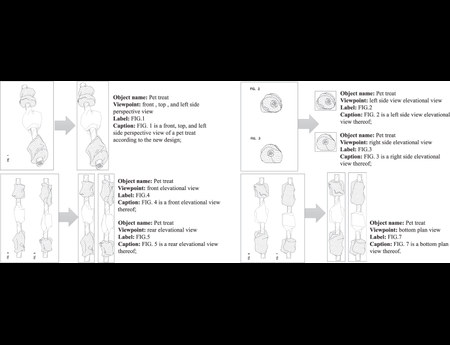
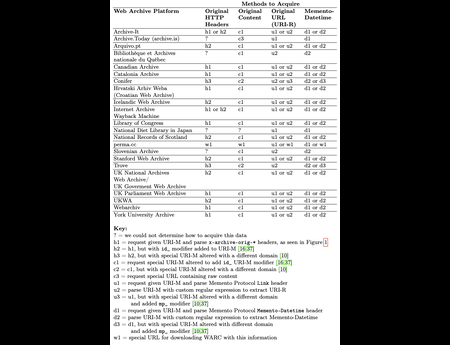
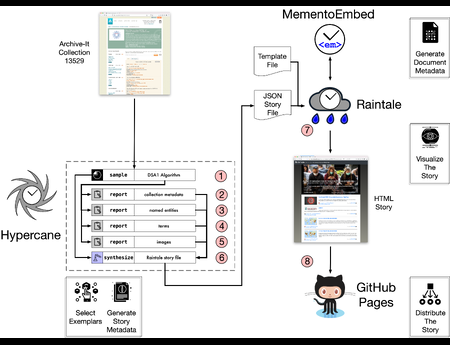
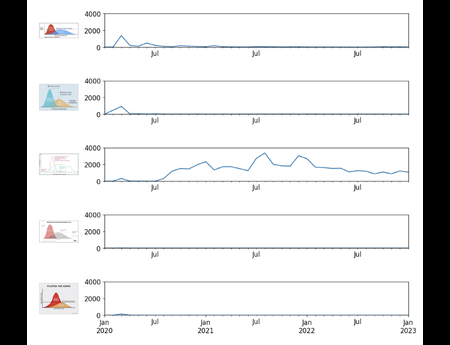
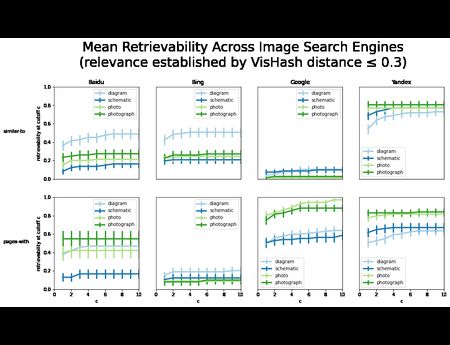
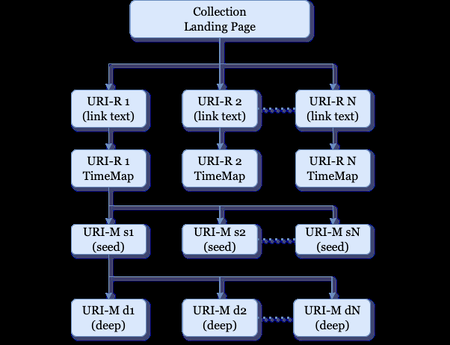
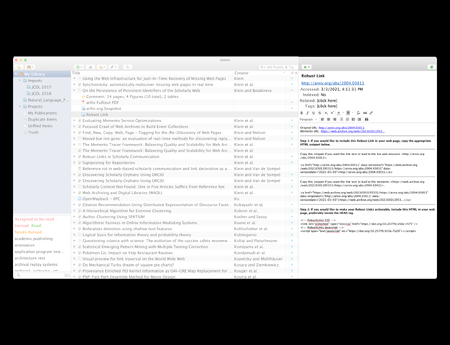
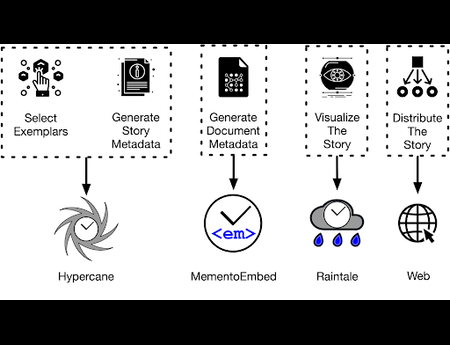
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}