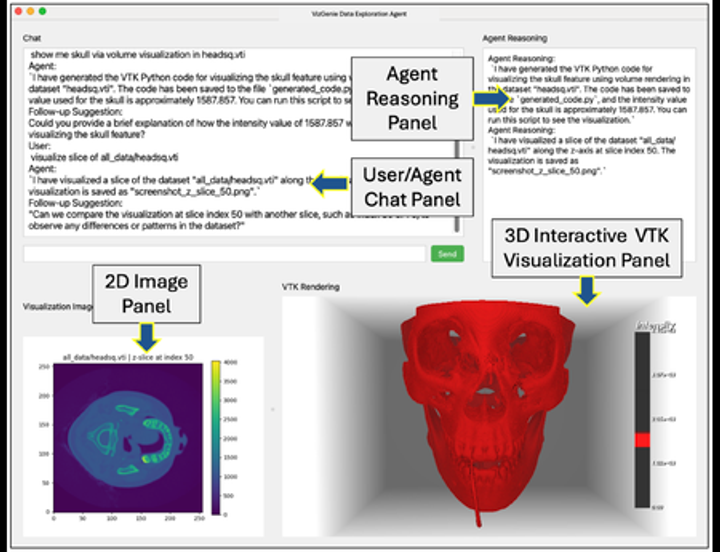
• Blog Post technical
Making Sure Your Prompt Will Be There For You When You Need It
By Shawn M. Jones
At Google, our team (Google Cloud Samples) uses Gemini to produce thousands of samples in batches. In doing so, we’ve learned that the biggest hurdle isn’t the AI, it’s our own expectations about these tools.