
• Blog Post casual fun
Hello Web
By Shawn M. Jones
Starting a new blog is throwing yourself out there. Welcome web traveler. I am Dr. Jones. Come in, I'll put on some tea.
Computer Scientist | Software Engineer | Cat Parent | Dreamer
From scientific research to software development to Seattle to IDIC, I am man of many hats and many worlds.

Starting a new blog is throwing yourself out there. Welcome web traveler. I am Dr. Jones. Come in, I'll put on some tea.
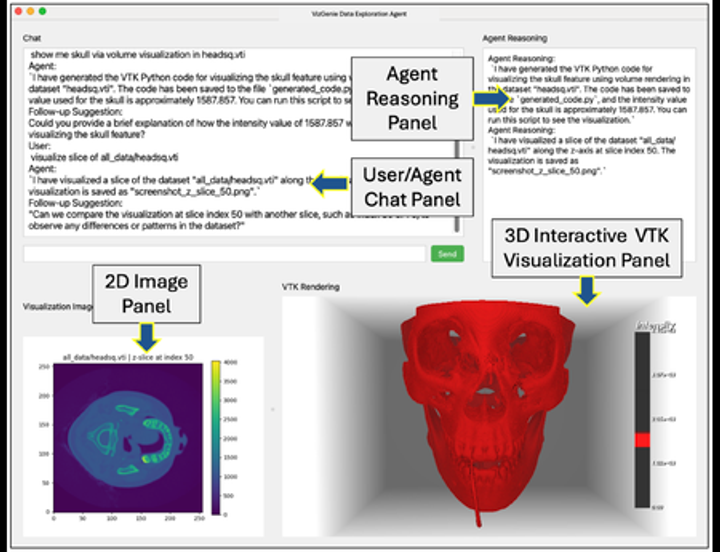
We present VizGenie, a self-improving, agentic framework that advances scientific visualization through large language model (LLM) by orchestrating of a...
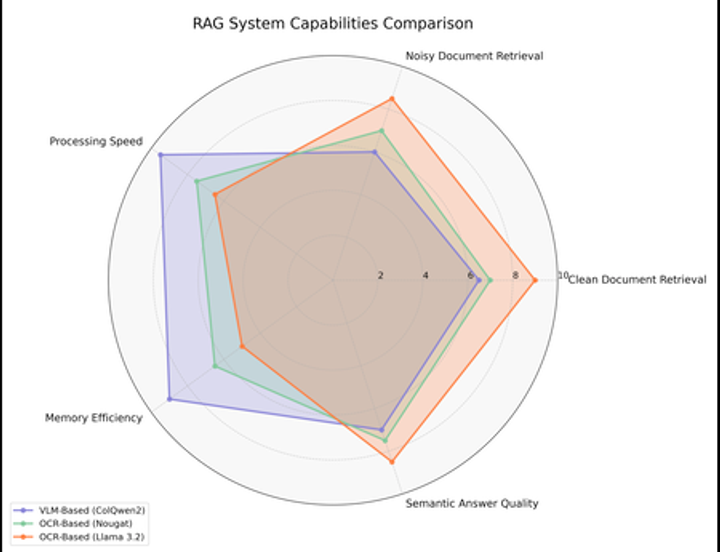
Retrieval-Augmented Generation (RAG) has become a popular technique for enhancing the reliability and utility of Large Language Models (LLMs) by groundi...